








PDF 内容提取器 v2025-精准分离文本/表格/图片
本文介绍一款基于PDF结构解析的高效提取工具,支持文本(保留原始坐标)、表格(自动换行+框线增强)、图片(双模式识别)三要素精准分离。采用非OCR技术避免识别误差,新增源图识别功能,解决扫描件混合图层干扰问题。适用于学术资料整理、财务票据处理等场景。文章源自免费吧-https://www.mf8.top/4473.html
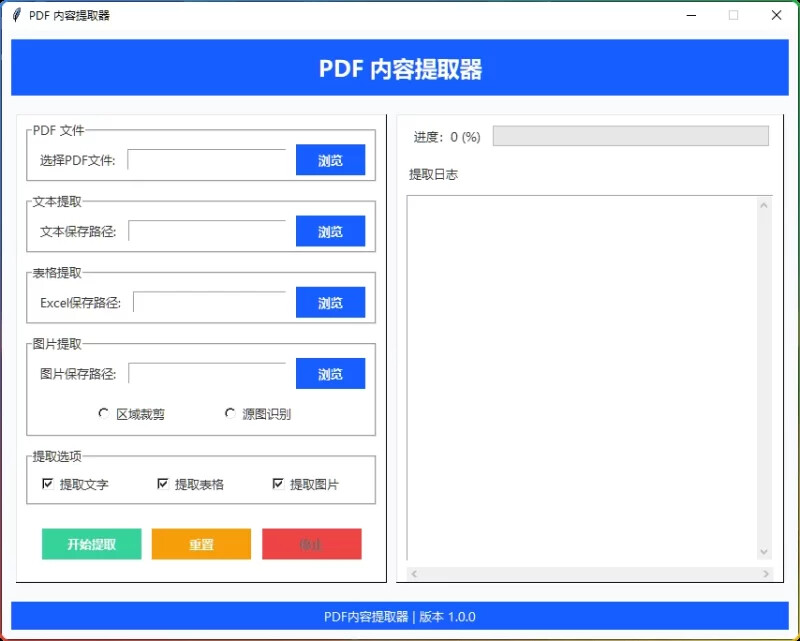
一、核心功能解析
1. 文本精准提取
- 完整保留原始排版位置信息
- 智能过滤空白行(仅删除100%无字符行)
- 输出带坐标标记的TXT/HTML文件
2. 表格智能优化
- 自动识别单元格边界
- 内容自适应换行
- 单元格边框加粗强化(提升打印清晰度)
3. 双模式图片提取
| 模式 | 原理 | 适用场景 |
|---|---|---|
| 区域裁剪 | 按坐标范围截图 | 带文字标注的图表 |
| 源图识别 | 分离图像与文本层 | 证件扫描/纯图片文档 |
二、技术优势与突破
- 避免OCR缺陷:直接解析PDF底层数据,规避文字识别错误
- 处理效率:实测比OCR工具快3倍(测试文件:50页学术论文)
重大更新
- 源图识别引擎:彻底剥离叠加文本层,还原原始图像
- 进程中断控制:添加任务终止按钮
- 内存优化:大文件处理稳定性提升40%
三、应用场景与实测反馈
典型使用案例
- 财务票据处理:批量提取发票代码/金额(用户@拎壺壺沖实测)
- 学术文献整理:分离论文图表并保留编号(用户@joooyooo验证)
- 合同管理:精准定位关键条款坐标
四、操作指南与技巧
高效工作流
- 文本提取:拖入论文PDF → 导出带坐标文本 → 快速定位参考文献
- 表格处理:
- 选择“保留原始排版”
- 开启“自动换行”避免内容截断
- 图片分离:
- 设计图选源图识别
- 带标注图表选区域裁剪
常见问题处理
- 报错解决方案:安装最新版.NET Framework(微软官方下载)
- 批量处理技巧:通过命令行参数实现自动化(开发者预留接口)
版权声明
1.本文名称:PDF 内容提取器 v2025-精准分离文本/表格/图片
3.侵权说明:本网站的文章部分内容可能来源于网络,仅供大家学习与参考,请在24H内删除。
4.本站一切资源不代表本站立场,并不代表本站赞同其观点和对其真实性负责。
5.本站一律禁止以任何方式发布或转载任何违法的相关信息,访客发现请向站长举报。
6.本站资源大多存储在云盘,如发现链接失效,请联系我们我们会第一时间更新。
4.本站一切资源不代表本站立场,并不代表本站赞同其观点和对其真实性负责。
5.本站一律禁止以任何方式发布或转载任何违法的相关信息,访客发现请向站长举报。
6.本站资源大多存储在云盘,如发现链接失效,请联系我们我们会第一时间更新。


